 Skip to content
Skip to content
Abstract: what are the boundaries and challenges of artificial intelligence? What is the current status of AI, and where should it head to? Experts in the field of artificial intelligence held a discussion at CCF youth summit 2019 (YEF 2019), an annual gathering of CCF held in Chengdu on May 24-25.
What are the boundaries and challenges of artificial intelligence? What is the current status of AI, and where should it head to? Experts in the field of artificial intelligence held a discussion at CCF youth summit 2019 (YEF 2019), an annual gathering of CCF held in Chengdu on May 24-25. Bo Zhang, the academician of the Chinese Academy of Sciences, said “Artificial intelligence has just started. It is not far from the starting point, and achieving AI is still a long way to go”
Although artificial intelligence technology is becoming more and more widely adopted in industry, as if we are in the industries with great investment potentialto embrace the next revolution, we should be cautiously optimistic about the development of artificial intelligence. Currently AI still faces many challenges, such as data silos, privacy protection, security issues, and how to develop from perceptual intelligence to cognitive intelligence and further to give machines self-awareness, etc. Addressing these challenges may be the key for the further development of AI.
Among all challenges, data silos and privacy protection are the prominent ones in the large-scale industrial application of artificial intelligence. To address those challenges professor Yang Qiang, an international expert on artificial intelligence and Chief Artificial Intelligence Officer of WeBank, delivered a specially invited report entitled “User Privacy, Data Silos and Federated Transfer Learning” at the conference. His answer is that research on a new generation of artificial intelligence algorithms will be carried out to break through the limitations of data silos and small data, while protecting data security and user privacy. What behind the answer is a new, world-leading technology called “Federated Transfer Learning.”

Small data and data silos are ubiquitous, big data era has not really come.
Professor Yang Qiang pointed out that the development of artificial intelligence is inseparable from big data. If artificial intelligence technology is the rocket engine, big data is the fuel. However, the explosively increasing of the data quantity does not indicate that the era of “big data” is coming. Most industries have only “small data” with low quality, and the problem of data silos is ubiquitous. There are many reasons that may cause data silos, including regulatory reasons, misaligned interests, process system restrictions and so on. For example, in the field of law, it requires a long period of time and the participation of judges, lawyers, and many other participants to label a sample. As a result, there are not many high-quality labeled data and those data are typically scattered among different courts.
From Transfer Learning to Federated Learning, break through data silos
Is there a technical solution? As the initiator and leader of transfer learning in the international artificial intelligence community, Professor. Yang Qiang seeks answers from transfer learning. The first thought to solve the “small data” problem is through knowledge transfer. More specifically, we can solve a machine learning task with only “small data” by conducting relevant machine learning tasks with “big data”. By this way, the established model can achieve better performance and it can be more reliable, robust, free from external interfere. The approach of transferring knowledge from a resource-rich source domain to a resource-poor target domain has been applied in finance, information flow recommendation and many other fields. Cases in point are the transferring of loan risk control strategy among different user categories, the transferring of recommendation strategy in the recommendation system and the transferring of keywords in the public opinion analysis system, etc.
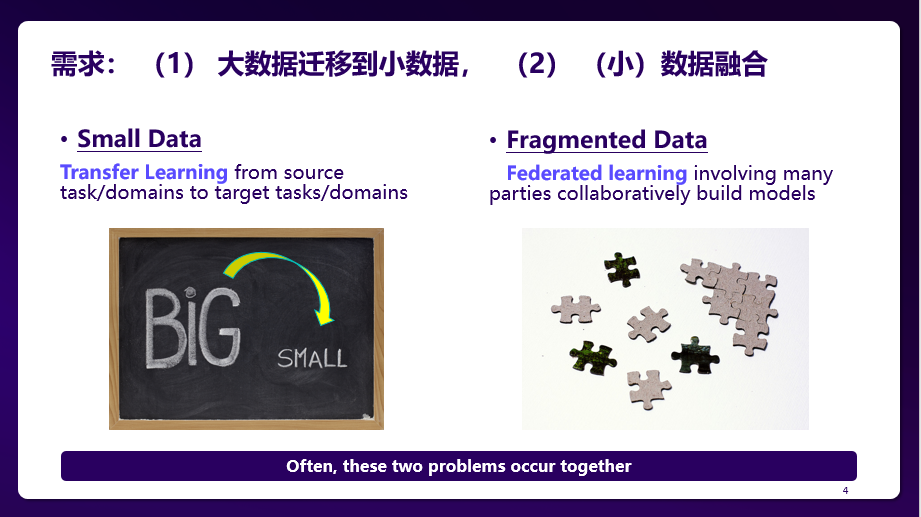
Although transfer learning can effectively solve the problem of “small data”, the problems that we are really facing now is not only the problem of “small data”, but also “data fragmentation” and “data silos”. They are not just technical problems and cannot be solved by simply integrating data. It requires overcome multi-dimensional problems such as policy, regulation, and technology. Federated Learning offers new ways to enable multiple parties to collaboratively build models without exchanging private user data.

From Federated Learning to Federated Transfer Learning, protecting data privacy
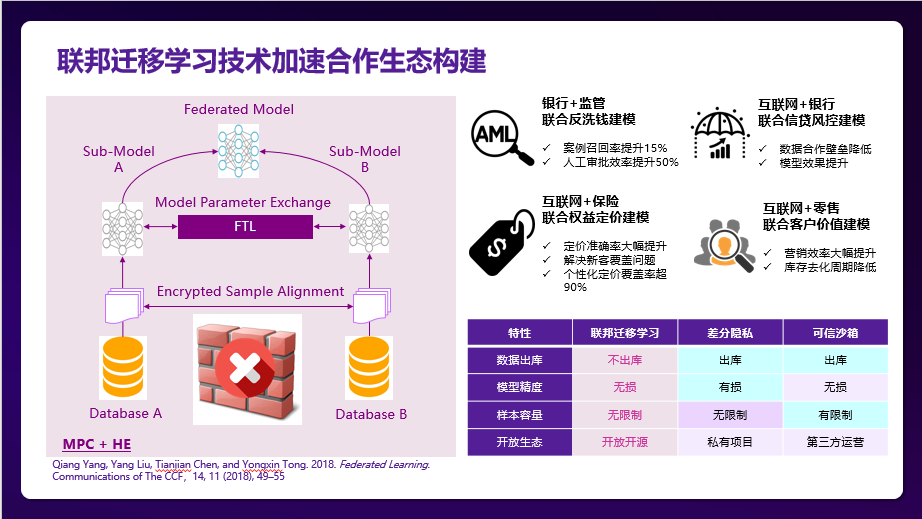
Integrating data and modeling together are supposed to be a nice direction but the increasingly strict protection of data privacy brings severe challenges. the “strictest” Data Privacy Protection law in history, GDPR (General Data Protection Regulation) is a signal that the whole world is strengthening the legislative construction of data privacy protection. Therefore, can the federated learning participants exchange only models while keeping data locally, thereby protecting data privacy? According to Professor Yang, mathematicians have come up with a new way to integrate homomorphic cryptography into federated learning. The core idea is not complicated. If A plus B is two terms in A formula and the whole formula is encrypted, then HE can express it as the encryption of A plus the encryption of B. By this way, participants only need to upload encrypted model parameters instead of raw data for collaborative model training. In this process, each party cannot reconstruct data of other parties even though multiple data exchanges may be required, so as to achieve data protection.
In practical applications, there is “horizontal federated learning” of different user groups based on the same feature dimension. For example, Google’s Federal Learning for mobile terminals, WeBank’s anti-money laundering model established with several Banks and “Vertical Federation” for the same user group with different feature dimensions, such as personalized insurance pricing based on the credit performance of users in the bank. In addition, WeBank’s AI team first proposed the “Federal Transfer Learning”, which combines the “federated learning” and “transfer learning”. Federated learning can be carried out even when the overlapping of user groups as well as the overlapping of feature dimensions are small. This means that cross-border cooperation can be achieved between government institutions and financial institutions, Internet institutions and financial institutions, or other fields.
Federated Learning is not only a technical direction, but it is a social issue
In addition to technology tools and Federated AI Technology Enabler (FATE), an open-source federated learning platform initiated by Webank, Professor Yang Qiang pointed out that it is crucial to set up an incentive mechanism to attract institutions into the federation and form a benign ecosystem. To establish such a federated ecosystem involves multiple fields such as game theory, mechanism design, law, and many other fields. Therefore, federated learning is not only a technical solution that can solve data silos and protect data privacy, but also a complex problem of social collaborative governance. In addition to attracting more enterprises to join the federated ecosystem, WeBank’s AI team is also actively promoting the development of the IEEE standard, an international standard for Federated Learning, which is expected to be released within two years to provide more technical basis for legislation and regulation.
What is the development direction of Federated Learning? Professor Yang Qiang pointed out that data can be kept locally and each data owner can exchange the parameters of machine learning models under the premise of security and confidentiality, to achieve collaborative modeling. This kind of integration of different disciplines is a trend, where federated learning, transfer learning, and other machine learning methods, can be combined and play to their strengths. This is a more valuable research from one field of artificial intelligence algorithm theory to multiple fields.